一、起始网址
1、点击新建任务后,第一步骤就是制作起始网址规则,点击向导添加,①➯②,出现如图界面。分3种方式:普通网址,批量网址,文本导入。
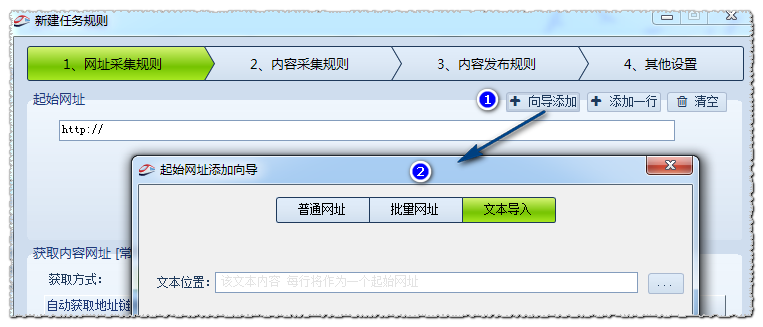
a.普通网址:以一行一个的形式直接加入网址,不做任何解析。
b.批量网址:以通用的表达式批量生成网址。
c.文本导入:以文本导入的形式,文本为一行一个的网址。
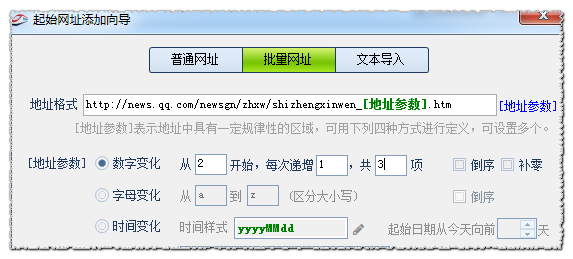
2,批量网址设置
此方法可以一次添加多个地址,需这些地址间有着某种关系,比如等差递增,或是字母a-z变化,
或是随时间变化,或自定义列表(自定义值一行一个)。
下面举例说明
比如我们批量添加这个列表分页 http://faq.locoy.com/qc-12.html?p=1
当我们点击第二页时,网址变化为http://faq.locoy.com/qc-12.html?p=2
由此可以分析得出,p的值就是分页页码,并且是每次加1递增,
所以设置如下图:
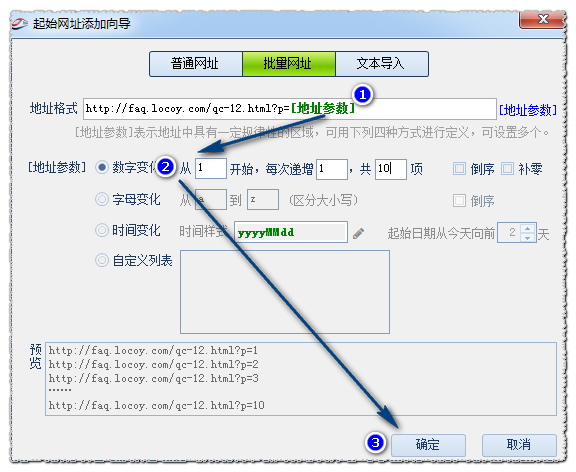
变化的部分本例是p等于的数字,我们用[地址参数]来表示,因为是数字所以我们选择数字变化类型。
因为我们第一页p=1,所以从1开始;
因为每次点击下一页,网址加1,所以每次递增1; 比如我们需要采集10页,那么就共10项
预览:采集器会按照上面设置的生成一部分网址,让你来判读添加的是否正确。
如果正确就点击下方的 确定 按钮。
二、获取内容网址
获取内容网址有常规模式和高级模式两种。
常规模式:该模式默认抓取一级地址,即从起始页源代码中获取到内容页A链接。
它有2种方式:a.自动获取地址链接 b.手动设置规则获取。
高级模式:该模式对0级,多级,POST类型网址的抓取有效。
即起始网址就是内容页网址;
或者需要对多级列表网址采集才能得到最终内容页链接;
或者是post网址类型抓取等情况下使用高级模式。
1、常规模式获取内容网站
自动获取地址链接:自动获取该级列表页中所有的a标签<a href=”URL”>内的URL链接
如新浪内地新闻:http://roll.news.sina.com.cn/news/gnxw/gdxw1/index.shtml
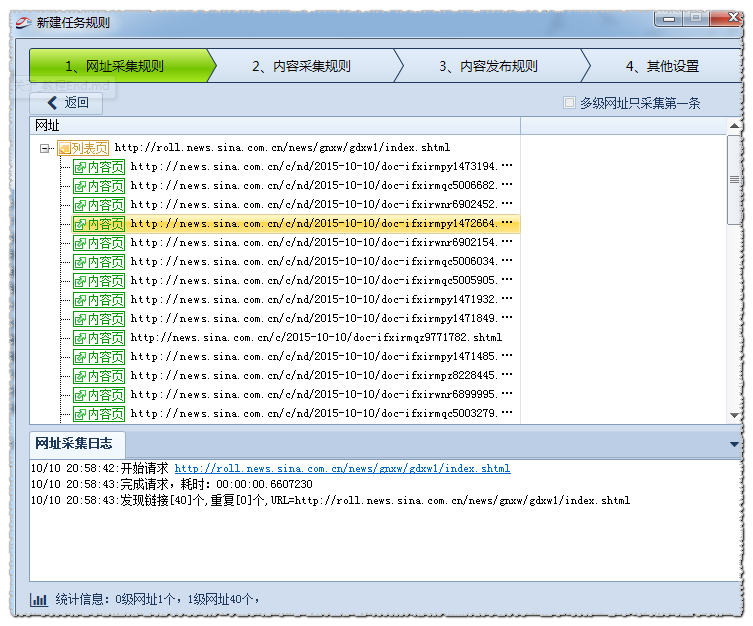
获取结果如图:
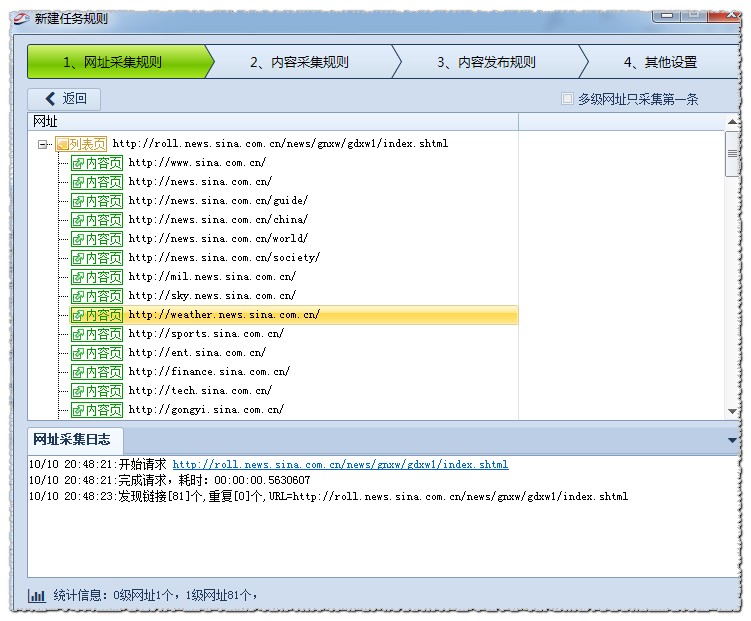
共81个一级网址,但实际我们需要抓取的1级网址是每页40个,
所以我们可以通过区域设置和链接过滤设置 来获取我们所需要的链接。
用谷歌浏览器在网页上右击——查看网页源代码,分析源码得出:
开始字符串为<ul class=”list_009″>
结尾字符串为 <!– 分页 begin –>
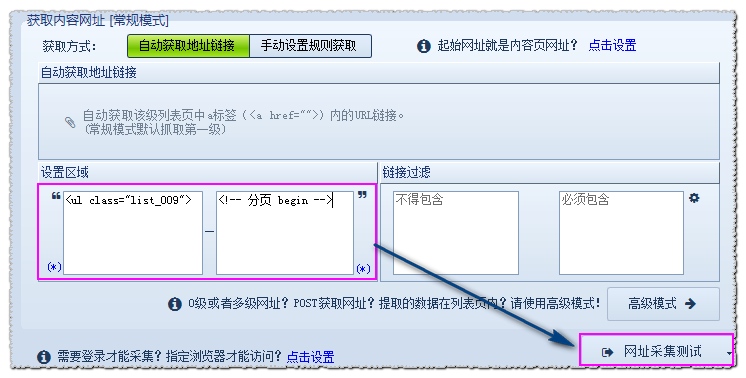
这样我们再点击网址采集测试,可以看出结果是正确的。
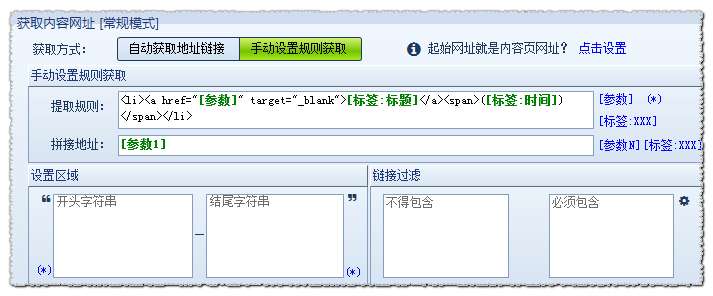
手动设置规则获取
对于有些由脚本生成的网址,采集器不能自动识别,此时就要手动设置规则获取了。
手动设置规则获取设置原理是编写脚本规则,去和源代码里的内容匹配,获取到自己设置的参数即可。
其中提取规则里的[参数],(*) ,[标签:XXX] 都是通配符,可以统配任意字符,
区别在于[参数]有返回值,一般用于拼接地址,(*)没有返回值,[标签:XXX]有返回值,返回值给标签。
如新浪内地新闻:http://roll.news.sina.com.cn/news/gnxw/gdxw1/index.shtml
有如下源码:
<li><a href="http://news.sina.com.cn/c/nd/2015-10-10/doc-ifxirmpy1472664.shtml" target="_blank">山西公布政府部门责任清单 建立拒腐机制</a><span>(10月10日 20:20)</span></li> <li><a href="http://news.sina.com.cn/c/nd/2015-10-10/doc-ifxirwnr6902154.shtml" target="_blank">河南登封市长被举报建寺涉贪 与释延鲁关系密切</a><span>(10月10日 20:14)</span></li> <li><a href="http://news.sina.com.cn/c/nd/2015-10-10/doc-ifxirmqc5006034.shtml" target="_blank">张家界国土局副局长涉严重违纪被查</a><span>(10月10日 19:45)</span></li>
此时,我们可以取其中的一条代码作为循环匹配,把我们要获取的链接替换成[参数],需要采集到的值替换成标签。 如:
<li><a href="[参数]" target="_blank">[标签:title]</a><span>([标签:time])</span></li>
2、高级模式获取内容网站
该模式对0级,多级,POST类型网址的抓取有效。
何为0级?起始网址就是内容页网址,直接采集起始网址里的内容。如图,点击 点击设置 按钮,从常规模式 跳转到 高级模式。此时[高级模式]-多级列表 为空,即起始网址会被当作内容页网址。  何为多级?即有多级列表,需要设置多级网址步骤后,才能得到最终内容页链接。先进入 [高级模式] 设置界面 每设置一级网址,则点击①添加一次,然后在对应的②处进行网址获取方式设置。 如图为2级网址采集:
何为多级?即有多级列表,需要设置多级网址步骤后,才能得到最终内容页链接。先进入 [高级模式] 设置界面 每设置一级网址,则点击①添加一次,然后在对应的②处进行网址获取方式设置。 如图为2级网址采集:
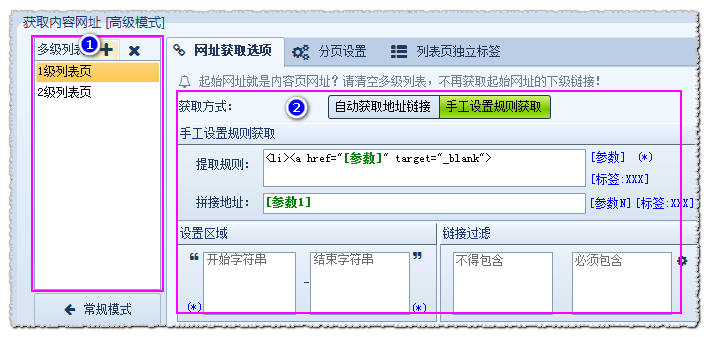
注:多级列表为空或者大于1级,不能切换到常规模式。可以先添加/删除至一级列表规则,再进行切换。
三、列表上下页分页
对于设置列表分页,下图的起始网址–批量网址设置是最常见也是最常用的。
现在我们用另外一种获取分页的办法,即通过列表上下页无限分页采集获取功能来自动获取分页。使用这个功能,起始页就只需要把首页地址添加进去就可以了,如下图:

然后进入[高级模式]-分页设置,设置区域开始字符串、区域结束字符串、地址样式、分页地址等字段。
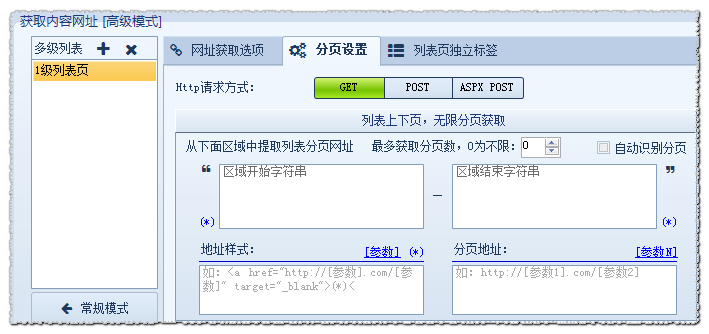
我们以http://news.qq.com/newsgn/zhxw/shizhengxinwen.htm 为例,我们看下第一页分页源代码的情况如下:

我们看下第二页分页源代码的情况如下:

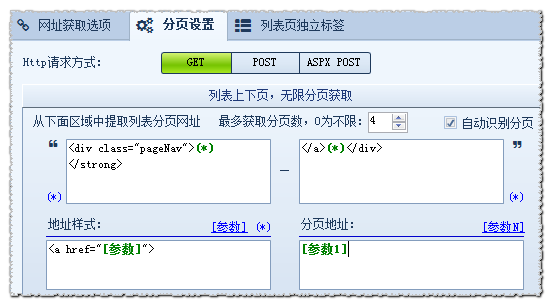
分析得出:当前页都是在<div class=”pageNav”>后的<strong></strong>这个代码后面紧接着一个<a href=””>就是下一页地址。 也就是说我们是要通过当前页获取下一页,这样一级一级的向下获取,直至把所有分页获取到。 所以,区域开始字符串为:<div class=”pageNav”>(*)</strong> 区域结束字符串为:</a>(*)</div>

地址样式根据截取区域的格式来写:<a href=”[参数]”> 效果如下:
四、登录采集
登录信息设置: 对于部分需要登录的网站,需要设置此项。

点击 点击设置 按钮,跳转到第四步其他设置——Http请求设置
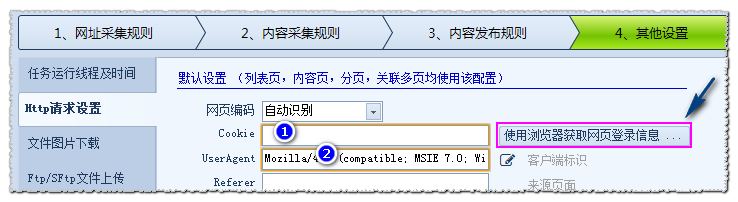
点击 使用浏览器获取网页登录信息 按钮,登录网址,输入账号密码后,再关闭窗口即可