一、标签编辑
对数据内容标签进行编辑定义,数据的获取方式有
A).从源码中获取数据
B).生成固定格式的数据
C).已有标签组合
A).从源码中获取数据:可精确地设置标签的来源是从默认页的源码、返回头信息和网页地址中,
或者是分页、循环分块、多页中。
其数据提取方式包括:
A.a).前后截取
A.b).正则提取
A.c).正文提取
A.d).Xpath提取
A.e).JSON 提取
B).生成固定格式的数据:可生成固定的字符串、系统时间、随机字符串、随机数字、系统时间戳、随机抽取信息
C).已有标签组合:可通过组合已有的标签,来生成新的标签内容
A.a).前后截取
通过设置开始字符串和结束字符串,来获取中间的字符,可以在开始和结束字符串中设置通配符(*)
A.b).正则提取
支持两种正则,一个纯正则,一个参数正则。
先介绍纯正则,举个例子,
如:前字符串 (?<content>[\s\S]*?)后字符串,这个正则其实效果跟前后截取一样,
如需要获取全部代码,则为^(?<content>[\s\S]*?)$ ,此功能运用需有一定的正则基础。
关于参数正则,是通过参数组合,来生成内容。
比如说要匹配标题为“新用户注册”和作者“神秘嘉宾”,代码如下:
<div class=”content”>
<h2>新用户注册</h2>
<div id=”tools”>【作者:神秘嘉宾】【字号:<a href=”#” class=”fontSize”>大</a>
设置如图:
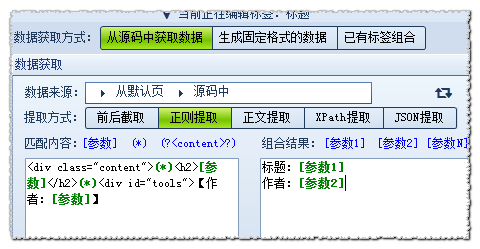
需要获取的字段用参数表示,不需要的字段或空格用星号代替;在组合结果里可以对多个参数进行组合。
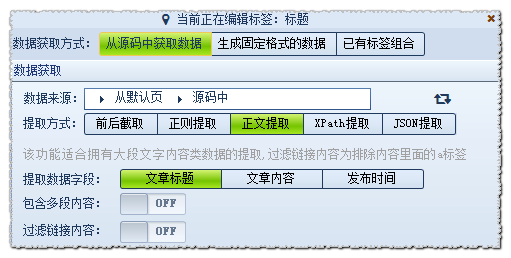
A.c).正文提取
注意这种方式只适合格式较为规则的多文字数据提取,例如新闻文章。
它不需要设置复杂的规则,可智能分析提取文章正文,文章标题,以及发布时间。
A.d).Xpath提取
通过Xpath表达式来获取数据,比如//div[@id=’content’],
就是获取id为content的div可指定要获取html节点的属性,
比如 Innerhtml、Outerhtml、Innertext、Href属性。
(注意:这种有一定的局限性,对于部分html标签不规范的页面无法解析。)
A.e).JSON提取
通过对JSON形式的数据格式化操作,写表达式来获取其节点数据。
二、数据处理
对从内容页面提取的数据进行进一步处理,可以同时添加多个操作,按照从上到下的顺序来执行。
也就是说,上个步骤的结果会作为下个步骤的参数。
1)提取内容为空:如果提取内容为空,则使用正则匹配从原始页面中再次提取
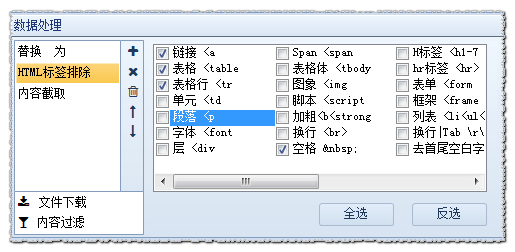
2)内容替换/排除:将采集到的内容进行字符串替换,如需排除,则替换为空字符串即可
3)html标签过滤:过滤指定html标签,比如<a ,<font
4)字符截取:通过开始和结束字符串对内容进行截取
5)纯正则替换:通过强大的正则表达式进行复杂的替换。
6)数据转换:包括将结果简转繁、将结果繁转简、自动转化为拼音和时间修正转化
7)智能提取:包括提取第一张图片、智能提取时间、智能提取邮箱、智能提取手机号码、智能提取电话号码
8)高级功能:包括自动摘要、自动分词、Http请求、字符编码转换、同义词替换、空内容缺省值、内容加前后缀、随机插入、运行C#代码、批量内容替换,统计标签字符串长度等一系列功能。
9)补全单网址:将当前内容作为一个网址进行补全。
10)文件下载:可以自动探测并下载文件,可设置下载路径和文件名样式。
11)内容过滤:对于一些不符合条件的记录,可以通过设置内容过滤来删除或标记为未采。
三、内容分页
内容分页有2种列出模式:a.首页全部列出,b.上下页模式。首页全部列出模式适用于分页地址全部显示出来的情况,如下图:上下页模式适用用分页地址仅列出一部分的情况,如下图

a.首页全部列出
我们以网址http://bbs.locoy.com/spider-140339-1-1.html为例,获取到整个分页区域的开始和结束
查看源代码:

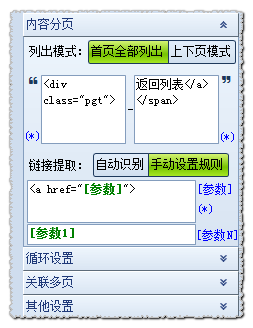
链接提取
链接提取有2种模式:自动识别;手动设置规则。
“自动识别”:采集器会在上面的设置的范围内,自动匹配到分页地址
“手动设置规则”:有的时候采集器识别分页的时候遇到无法识别或者识别的不是很准确,
我们就可以把分页的格式写上去,来确保识别分页的正确性。
本例中我们用“手动设置规则”给大家讲解
取a链接代码格式放入,将其中需要获取的分页地址,用[参数]表示,然后在下面进行[参数1]组合,若有多个参数,依次为[参数1],[参数2],[参数3]…;若[参数1]不是绝对地址,则相应补全拼接为绝对地址。
设置如下图
四、循环设置
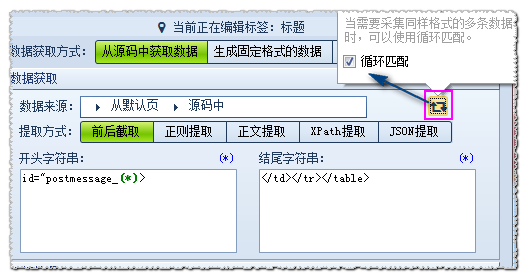
当需要采集同样格式的多条数据时,可以根据其中一条信息格式进行设置,然后使用循环匹配。
我们以网址http://bbs.locoy.com/spider-140339-1-1.html为例,
来获取获取它的主题内容和回复内容。
查看源代码,分析得到:
主题内容开始字符串为id=”postmessage_649823″> 因为不同的帖子,ID不同,
所以我们把649823这个数字设置为(*)通配符.
即开头字符串为id=”postmessage_(*)”>
结尾字符串为</td></tr></table>
然后勾选下图中的循环匹配,即可实现主题和回复的内容采集。
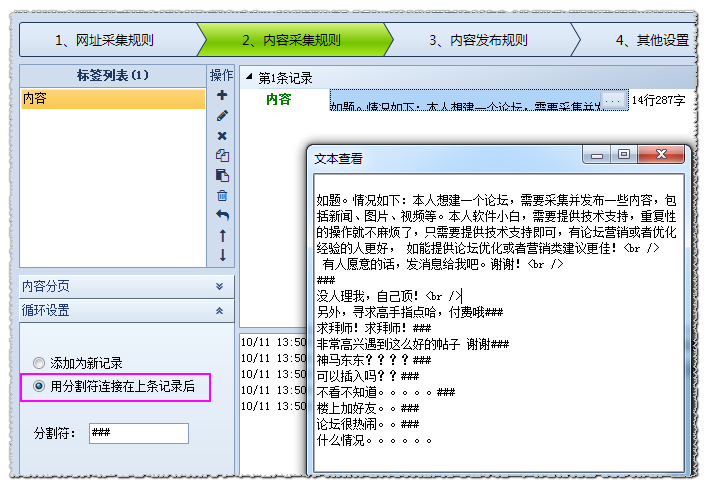
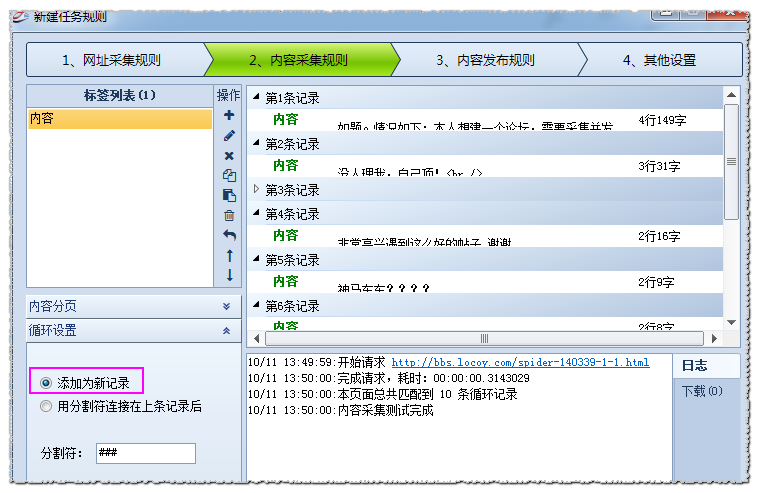
循环设置——添加为新记录
此方式采集到的每条记录都为单独的行存储在数据库中
循环设置——用分隔符连接在上条记录后此方式采集到的多条记录用分隔符(默认###,可自行修改)连接在一起存储在一个字段内,如下图: